교수님은 정보보다는 지식에 초점을 더 맞추어야 한다고 강조하셨습니다. 정보의 일방적인 습득은 학습에 큰 의미가 없다는 사실도 말씀하셨구요. 정보에서 맥락이 바뀐다면 그 정보는 의미가 없기 때문입니다.
그런데 지식(knowledge)보다 상위 단계는 없을까요?
(3) 지혜 (Wisdom)
지식의 상위 단계는 바로 지혜입니다. 지혜는 경험, 지식, 훌륭한 판단을 갖춘 자질을 뜻하는데요.
효율과 효과 외에, 윤리와 도덕을 고려하여 상황을 판단해야 합니다.
2. 자연어 처리
(1) DIKW Pyramid와 인공지능
앞서 말한 4가지는 DIKW Pyramid로 구성할 수 있습니다.
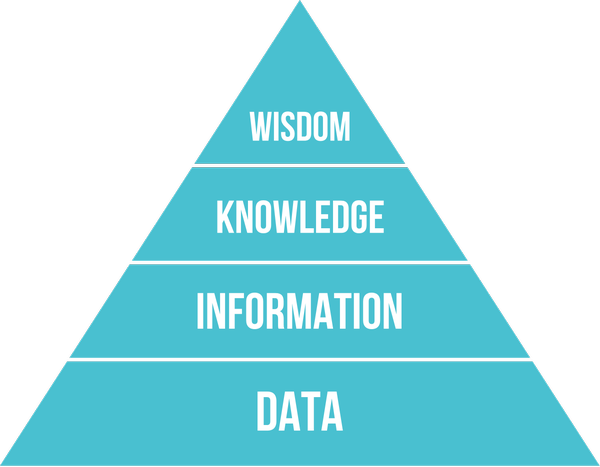
데이터에서 프로세싱을 한 후, 정보 인지를 하고 나면 비로소 지식이 됩니다. 지식에서 판단이 일어난다면 가장 상위 단계인 지헤로 가게 되어 Shared Understanding이 일어난다고 합니다.
데이터 마이닝 (Data Mining)은 Raw data로부터 필요한 데이터나 정보를 찾는 행위를 뜻합니다.
이를 활용하여 정보를 추출하고 검색할 수 있는데, 이는 정형화된 데이터 집합으로부터 필요한 정보를 추출하거나 검색할 수 있다는 뜻입니다. 정보 추출/검색(Information Extraction/Retrieval)은 자연어 처리의 중요한 하위 분야 중 하나입니다.
지식 표현 (Knowledge Representation)은 사람의 지식을 컴퓨터가 이해할 수 있도록 논리학 또는 기호학 등을 이용해 표현할 수 있습니다.
이를 통해 머신 러닝(Machine Learning), 즉 기계 학습을 시행할 수 있는데요.
기계가 학습을 통해 새로운 데이터 또는 정보가 주어졌을 때 자동으로 분류, 군집, 또는 예측할 수 있습니다.
(2) 빅 데이터 (Big Data)
빅 데이터는 디지털 환경에서 생성되는 데이터로 그 규모가 방대하고, 생성 주기도 짧고, 형태도 수치 데이터뿐 아니라 문자와 영상 데이터를 포함하는 대규모 데이터를 말하는데요. 빅데이터 환경은 과거에 비해 데이터의 양이 폭증했다는 점과 함께 데이터의 종류도 다양해져 사람들의 행동은 물론 위치정보와 SNS를 통해 생각과 의견까지 분석하고 예측할 수 있습니다.
- 빅 데이터의 활용 케이스
1) 로그 데이터 분석
로그 데이터를 분석하여 가동 중인 컴퓨터 시스템 내에서 발생하는 장애에 대처하기 위해 데이터 장애 발생 직전의 상태로 복원할 수 있습니다.
2) 전자 상거래 개인화
소비자의 구매 성향을 파악하여 소비자에게 가장 적합한 상품들을 보여줄 수 있습니다.
3) 추천 시스템
도입부에 언급했던 Spotify나 Netflix와 같이 사용자의 선호 데이터를 분석하여 사용자에게 음악이나 영상을 추천할 수 있습니다.
4) 구직자 자동 추천 및 배치
5) 보험 사기 검출
최근 보험 사기가 일어났던 데이터를 분석하여 보험 사기를 검출합니다. 이는 비정상 상태 검출(Anomaly Detection)의 예시입니다.
- 게임에서의 빅데이터 사용 사례
유럽에서 초등 4학년에서 중학생 정도 사이에서 많이 플레이하는 게임인 'Movie Star Planet'이라는 게임이 있습니다. 이 게임은 Social Game 장르로, Online Predator Detection에 빅데이터 및 기계학습 알고리즘을 적용하여 게임을 운영하고 있습니다.
(3) 인공지능에서의 빅 데이터
인공지능에서의 빅 데이터를 소개하기 전, 교수님의 Game AI 클래스에서 "지능이란 무엇인가?" 라는 질문을 하셨다고 합니다. 이 때 수강생들의 대답을 가져오셨는데요.
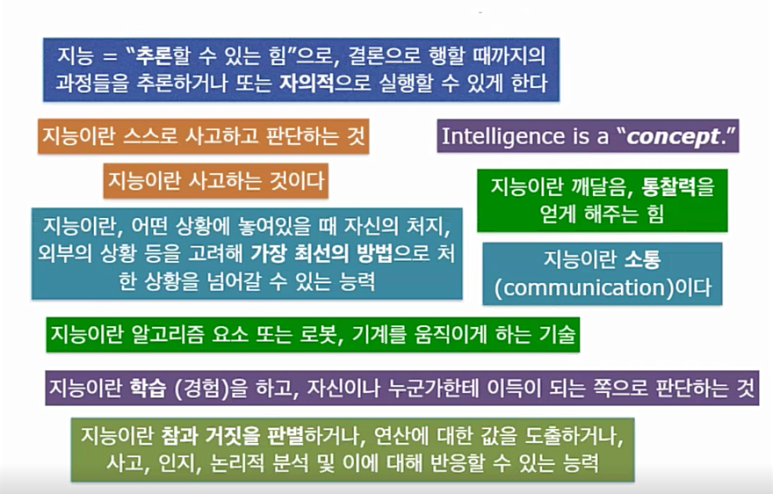
이러한 다양한 답변이 나왔습니다.
지능(Intelligence)이란 무엇인가? 에 대한 질문과 이에 대한 의견은 1950년 Alan Turing에 의해 공식적으로 제기되었습니다.
이 때 앨런 튜링은 The Imitation Game이라는 실험을 고안하여 "Mind" 저널에 투고하면서 제안했습니다.
게임에서 판사, 남자, 여자로 구성된 게임 참가자들은 모든 채팅은 이메일을 통해 교환합니다. 남자는 거짓말을 할 수 있으며, 여자인 척을 하고 여자는 진실을 이야기하고 판사를 도우려고 합니다. 판사는 5분 이내에 어느 쪽이 남자인지 판별해야 하는 게임입니다.
- 튜링 테스트 (Turing Test)
이와 같은 실험을 진행한 후, 앨런 튜링은 튜링 테스트를 고안했습니다. 1950년 튜링은 〈계산기계와 지성〉이라는 논문을 통하여 기계(컴퓨터)가 사람처럼 생각할 수 있다는 견해를 제시하였습니다. 그는 이 논문에서 컴퓨터와 대화를 나누어 컴퓨터의 반응을 인간의 반응과 구별할 수 없다면 해당 컴퓨터가 사고할 수 있는 것으로 간주하여야 한다고 주장하였으며, 50년 뒤에는 보통 사람으로 구성된 질문자들이 5분 동안 대화를 한 뒤 컴퓨터의 진짜 정체를 알아낼 수 있는 확률이 70%를 넘지 않도록 프로그래밍하는 것이 가능해질 것이라고 예견하였습니다.
튜링 테스트는 기계가 지능을 가질 수 있다는 생각과 이를 언어를 통해 테스트할 수 있다는 생각을 그 당시까지 아무도 생각하지 못했기에 AI 역사에서 매우 중요한 의미를 가집니다. 튜링 테스트에 기반한 컨셉은 현재까지도 영화나 TV 예능 같은 곳에서 자주 볼 수 있습니다.
- 다트머스 회의 (Dartmouth Workshop)
1956년, 앨런 튜닝이 비극적으로 죽은 지 2년이 지난 후 미국 동부에 있는 Dartmouth College에서 인공지능에 관심있는 11명의 학자들이 모여 소모임 "Dartmouth Workshop"을 갖습니다. 이 때 최초로 인공 지능(Artificial Intelligence)라는 용어가 소개되었습니다.
최근 AI는 물체 인식, 언어 인식과 생성, 감성 인식 등 다양한 분야에서 상당한 발전을 이루었고, 여기에는 딥 러닝 (Deep Learning) 알고리즘의 개발이 큰 영향을 끼쳤습니다. 딥 러닝의 기반이 되는 기술은 인공 지능 역사에서 중요한 역할을 차지하는 인공 신경망 (Artificial Neural Network; ANN or NN)입니다.
- IBM Deep Blue (1997)
IBM 사가 개발한 딥 블루는 1997년 역사상 가장 위대한 기사로 손꼽히는 전 체스 챔피언, 가리 카스파로프(Garry Kasparov)와 체스로 대결한 인공지능 로봇입니다. 딥 블루는 카스파로프를 이겨 가장 고도화된 두뇌 게임의 세계에서 군림하던 인간 챔피언을 무너뜨린 기계가 되었고, 인공지능이라는 새로운 시대의 개막을 알리는 신호탄이었습니다.
- IBM Watson in Jeopardy! (2011)
왓슨은 자연어를 사용하는 문답 컴퓨터 시스템으로, Jeopardy!라는 유명한 퀴즈 쇼에서 우승한 인공지능입니다. 위키피디아에 있는 정보들을 지식 베이스에 저장하였다가, 질문을 해석한 후 필요한 정보를 지식 베이스로부터 가져와 질문에 대답하며 가벼운 대화를 생성할 수도 있습니다.
- Deep Mind (Google) AlphaGo (2016)
우리나라 사람에게 아마도 가장 유명한 인공지능일 겁니다. 알파고는 바둑을 플레이하는 컴퓨터 프로그램입니다. 2016년 3월9일부터 15일까지 이세돌 9단과 펼친 세기의 바둑대결, 경기전에 이세돌 9단이 우세할 것이라는 의견이 지배적이었지만 알파고가 4대 1의 대승을 거두었습니다. 알파고의 승리는 한국은 물론 전세계에 엄청난 충격을 몰고 왔고, “인공지능이 인간을 지배하는 세상이 올 것”이라는 두려움마저 생겼습니다.
앞서 언급한 컴퓨터 프로그램들은 딥 러닝을 활용하여 만든 인공지능입니다.
딥 러닝 (Deep Learning)은 인공 신경망 기술 중 하나로, 오토인코더, 합성곱 신경망, 순환 신경망 등의 학습 알고리즘을 이용하여 학습합니다. 일반적인 Neural Network와 비교해서 은닉층의 개수가 많고 깊습니다. 데이터의 양이 커질수록 계산 속도 향상을 위해 하드웨어 그래픽 카드 (GPU)에 많이 의존하는 경향이 있습니다. 기존의 AI 알고리즘보다 매우 좋은 성과를 보여주고 있지만, 왜 결과가 잘 나오는지 이해할 수 있게 설명하기가 어렵습니다. 이 단점을 통해 "eXplainable AI (XAI)" 연구에 대한 관심이 증가하고 있습니다.
(4) NLP가 뭘까?
NLP는 컴퓨터가 자연어 (Natural Language)를 이용해서 입력과 출력을 처리하도록 하는 것입니다. 다루는 주제에 따라서 NLG (Natural Language Generation)와 NLU (Natural Language Understanding)으로 구분합니다.
- NLP에서 일반적 절차
1) Preproocessing (전처리) : 노이즈 제거
2) Lexical Analysis (단어 분석)
3) Syntactic Analysis (구문, 문법 분석) : 형태소, 품사 분석
4) Semantic Analysis (의미 분석) : 문장 단위
5) Discourse Analysis (담화 분석) : 문장 간 관계 분석을 통해 전체를 이해
- NLP 연구 주요 방법
1) 지식, 규칙 기반의 기호적 방법 (Symbolic approach)
사람이 수동으로 지식 또는 규칙을 정의하고 구축하는 방법으로, 많은 시간과 비용이 필요합니다.
2) 데이터 기반의 통계적/확률적 방법 (Statistical/Probabilistic approach)
수동 또는 자동으로 태깅(Tagging) 또는 레이블링(Labeling)한 데이터셋(Corpus)가 필요합니다.
최근 연구의 주류는 딥러닝 기반 방법입니다.
- NLP 응용/세부 분야
: 오탈자, 문법 교정, 정보 추출, 음성 인식, 정보 검색, 요약, 기계 번역, 질의 응답, 대화 시스템 등....
예) 인과 관계 분석, Apple Siri, 뉴스 기사 자동 요약, 챗봇
3. 감성 분석 (Sentiment Analysis) 및 GPT-3 언어 모델을 이용한 자연어 생성 사례
(1) 감성 분석 (Sentiment Analsis)
소비자의 감성과 관련된 텍스트 정보를 자동으로 추출하는 텍스트 마이닝(Text Mining) 기술의 한 영역으로. 문서를 작성한 사람의 감정을 추출해 내는 기술로 문서의 주제보다 어떠한 감정을 가지고 있는가를 판단하여 분석합니다.
주로 온라인 쇼핑몰에서 사용자의 상품평에 대한 분석이 대표적 사례로 하나의 상품에 대해 사용자의 좋고 나쁨에 대한 감정을 표현한 결과입니다. 또한 소셜 미디어나 영화 리뷰 등 인터넷에 올라오는 글을 실시간으로 수집하고, 여휘의 긍정-부정성을 매칭하여 사람들의 기분을 예측하는 기술입니다.
(2) GPT-3 언어 모델
https://youtu.be/jz78fSnBG0s
이 영상을 보시면 두 사람의 대화가 아주 자연스러운 것을 알 수 있습니다.
사실 두 사람은 실제 인물이 아닌 가상의 인물들인데요. openAI 사가 만든 GPT-3라는 언어 모델을 이용하여 구현한 대화 영상입니다.
GPT-3 언어 모델은 딥러닝을 이용해 인간다운 텍스트를 만들어내는 자기회귀 언어 모델입니다. GPT-3의 전체 버전은 1,750억 개의 매개변수를 가지고 있어 각종 언어 관련 문제풀이나 랜덤 글짓기, 간단한 사칙연산, 번역, 그리고 주어진 문장에 따른 간단한 웹 코딩이 가능합니다.
GPT-3를 끝으로 이번 특강은 막을 내렸습니다.
데이터부터 GPT-3까지, 단 2시간 만에 인공지능과 자연언어처리의 사례에 대해 배워볼 수 있었습니다.
비전공자도 알기 쉽게 모든 개념을 예시를 들어가며 설명해주신 교수님 덕분에 지식의 깊이가 한층 더 깊어진 것 같습니다.
앞으로도 다양한 특강이 있다면 놓치지 않고 들어야겠습니다!
특히 이러한 특강들은 대학혁신지원사업의 지원을 받아 진행하는 프로그램이라 양질의 특강을 들을 수 있습니다.
관심있는 학우 분들은 언제든지 학교 홈페이지 공지사항에 특강 공고가 올라오면 들을 수 있습니다.
앞으로도 많은 참여 부탁드립니다 ( ´╹ᗜ╹`*)
서울캠퍼스 공지사항 : http://www.hongik.ac.kr/contents/www/cor/studentsno.html
세종캠퍼스 학생공지 : http://www.hongik.ac.kr/contents/www/cor/sejong.html